Introduction
In this section, we show a few R functions for exploring NCDS data; as noted, historical sweeps of the NCDS did not use modern metadata standards, so finding a specific variable can be challenging. Variables do not always have names that are descriptive or follow a consistent naming convention across sweeps. (The variable for cohort member sex is N622, for example.) In what follows, we will use the R functions to find variables for cohort members’ height, which has been collected in many of the sweeps.
The packages we will use are:
# Load Packages
library(tidyverse) # For data manipulation
library(haven) # For importing .dta files
library(labelled) # For searching imported datasets
library(codebookr) # For creating .docx codebooks
labelled::lookfor()
The labelled package contains functionality for attaching and examining metadata in dataframes (for instance, adding labels to variables [columns]). Beyond this, it also contains the lookfor() function, which replicates similar functionality in Stata. lookfor() also one to search for variables in a dataframe by keyword (regular expression); the function searches variable names as well as associated metadata. It returns an object containing matching variables, their labels, and their types, etc.. Below, we read in the NCDS 55-year sweep dataset which contains derived variables (55y/ncds_2013_derived.dta) and use lookfor() to search for variables related to "height".
ncds_55y <- read_dta("55y/ncds_2013_derived.dta")
lookfor(ncds_55y, "height")
pos variable label col_type missing values
46 ND9HGHTM (Derived) Height in metres dbl+lbl 0 [-8] No information
Users may consider it easier to create a tibble of the lookfor() output, which can be searched and filtered using dplyr functions. Below, we create a tibble (a type of data.frame with good printing defaults) of the lookfor() output and use filter() to find variables with "height" in their labels. Note, we convert both the variable names and labels to lower case to make the search case insensitive.
ncds_55y_lookfor <- lookfor(ncds_55y) %>%
as_tibble() %>%
mutate(variable_low = str_to_lower(variable),
label_low = str_to_lower(label))
ncds_55y_lookfor %>%
filter(str_detect(label_low, "height"))
# A tibble: 1 × 9
pos variable label col_type missing levels value_labels variable_low
<int> <chr> <chr> <chr> <int> <name> <named list> <chr>
1 46 ND9HGHTM (Derived) He… dbl+lbl 0 <NULL> <dbl [1]> nd9hghtm
# ℹ 1 more variable: label_low <chr>
codebookr::codebook()
The NCDS datasets that are downloadable from the UK Data Service come bundled with data dictionaries within the mrdoc subfolder. However, these are limited in some ways. The codebookr package enables the creation of data dictionaries that are more customisable, and in our opinion, easy to read. Below we create a codebook for the NCDS 55-year sweep derived variable dataset. These codebooks are intended to be saved and viewed in Microsoft Word.
cdb <- codebook(ncds_55y)
print(cdb, "ncds_55y_codebook.docx") # Saves as .docx (Word) file
A screenshot of the codebook is shown below.
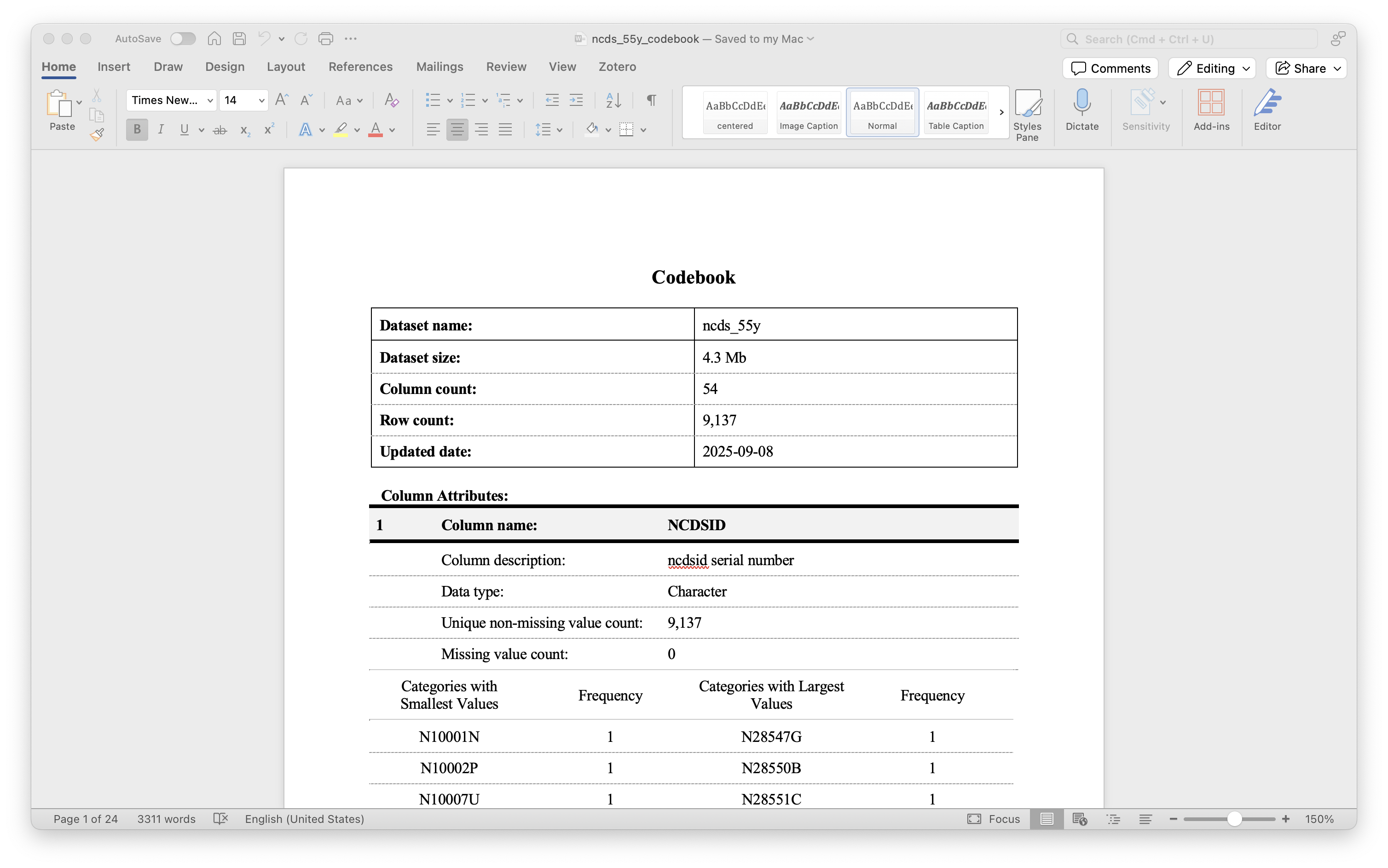
Create a Lookup Table Across All Datasets
Creating the lookfor() and codebook() one dataset at a time does not allow one to get a quick overview of the variables available in the NCDS, including the sweeps repeatedly measured characteristics are available in. Below we create a tibble, df_lookfor, that contains lookfor() results for all the .dta files in the NCDS folder.
To do this, we create a function, create_lookfor(), that takes a file path to a .dta file, reads in the first row of the dataset (faster than reading the full dataset), and applies lookfor() to it. We call this function with a mutate() function call to create a set of lookups for every .dta file we can find in the NCDS folder. map() loops over every value in the file_path column, creating a corresponding lookup table for that file, stored as a list-column. unnest() expands the results out, so rather than have one row per file_path, we have one row per variable.
create_lookfor <- function(file_path){
read_dta(file_path, n_max = 1) %>%
lookfor() %>%
as_tibble()
}
df_lookfor <- tibble(file_path = list.files(pattern = "\\.dta$", recursive = TRUE)) %>%
filter(!str_detect(file_path, "^UKDS")) %>%
mutate(lookfor = map(file_path, create_lookfor)) %>%
unnest(lookfor) %>%
mutate(variable_low = str_to_lower(variable),
label_low = str_to_lower(label)) %>%
separate(file_path,
into = c("sweep", "file"),
sep = "/",
remove = FALSE) %>%
relocate(file_path, pos, .after = last_col())
We can use the resulting object to search for variables with "height" in their labels.
df_lookfor %>%
filter(str_detect(label_low, "height")) %>%
select(file, variable, label)
# A tibble: 79 × 3
file variable label
<chr> <chr> <chr>
1 ncds0123.dta n510 0 Height of mum in inches at chlds brth
2 ncds0123.dta n332 1M Childs height, no shoes-nearest inch
3 ncds0123.dta n334 1M Childs height,no shoes-to centimeter
4 ncds0123.dta n1199 2P Father's height in inches
5 ncds0123.dta n1205 2P Mothers height in inches
6 ncds0123.dta n1510 2M Childs height no shoes,socks- inches
7 ncds0123.dta n1511 2M Fractions of an inch in childs height
8 ncds0123.dta n1949 3M Child's height,in bare feet,in cms
9 ncds0123.dta dvht07 1D Height in metres at 7 years
10 ncds0123.dta dvht11 2D Height in metres at 11 years
# ℹ 69 more rows